
StyleSSP

第一次详细的讲解论文,可点击跳转论文页面
StyleSSP: Sampling StartPoint Enhancement for Training-free Diffusion-based Method for Style Transfer
(ZJU)Xu 等,CVPR 2025
2025/12/04
背景
- 风格迁移:保持内容布局不变,把风格图像的笔触/颜色/纹理迁移到内容图像上
- 现有免训练(training-free)扩散方法存在两大问题:
- 内容保持问题:布局/语义被破坏,叠加 ControlNet 仍效果不好
- 风格图像泄漏:风格图里的物体被带入生成结果,“污染”生成内容
- 发现:采样起点(startpoint)的质量对内容保持与风格泄漏影响极大


相关工作
- 训练型:如 DEADiff,依赖内容相同、风格不同的成对数据集,训练开销大却并未体现相应规模扩散模型在生成方面该具备的压倒性优势,泛化依然较差
- 免训练:泛化强,使用便捷,但 StyleID 与 InstantStyle plus 等靠特征/prompt 融合改善内容保持。强调过反演对内容保持的重要性,仍存在内容漂移与泄漏现象
- 起点作用:已有工作关注采样阶段负引导或简单 rescale 起点(StyleID)以抵消颜色影响,但缺少对采样起点在风格迁移中具体效果的研究
动机
Diffusion Model
- 多条件控制易因初始偏好不平衡而失效,实验结果(如图)表明在 DDIM 反演阶段施加负引导,比采样阶段负引导更能让起点远离风格内容,从而缓解内容泄漏与配色偏移

Frequency Analysis
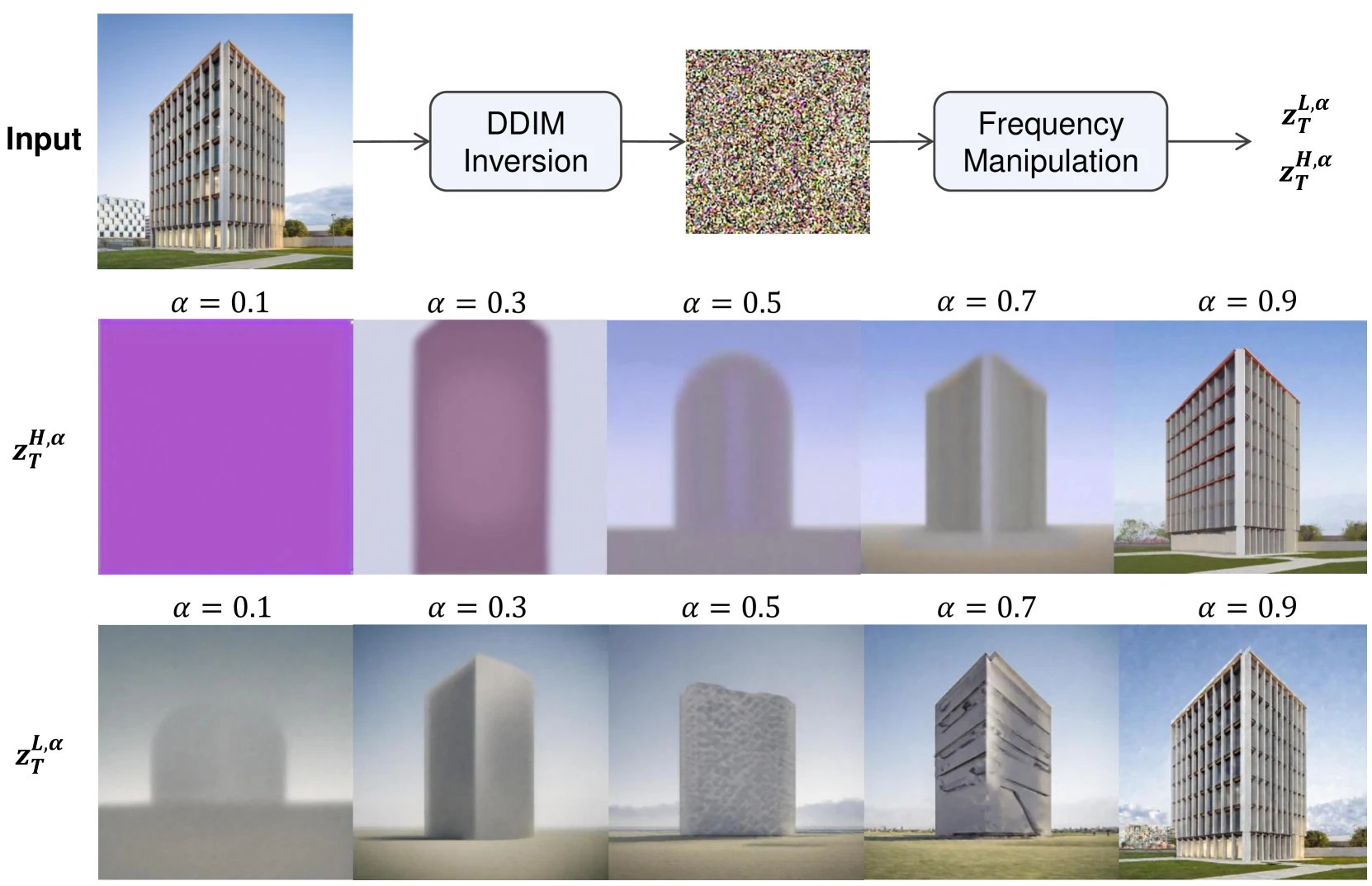
- 频域上高频决定轮廓/布局,低频对布局帮助小,参考 FlexiEdit 等研究发现高频保真可显著减小布局漂移
核心思路
- 更好的初始噪声(采样起点)能同时改善内容保持与抑制风格泄漏
- 聚焦采样起点增强做出了两个改进:
- 频率操作(Frequency Manipulation):削弱 DDIM 潜变量(latent)的低频成分,强化布局保持
- 负引导(Negative Guidance):在反演(Inversion)阶段远离风格内容,降低风格图样式泄漏
- 结合 InstantStyle plus 式的风格注入 + ControlNet 做内容约束
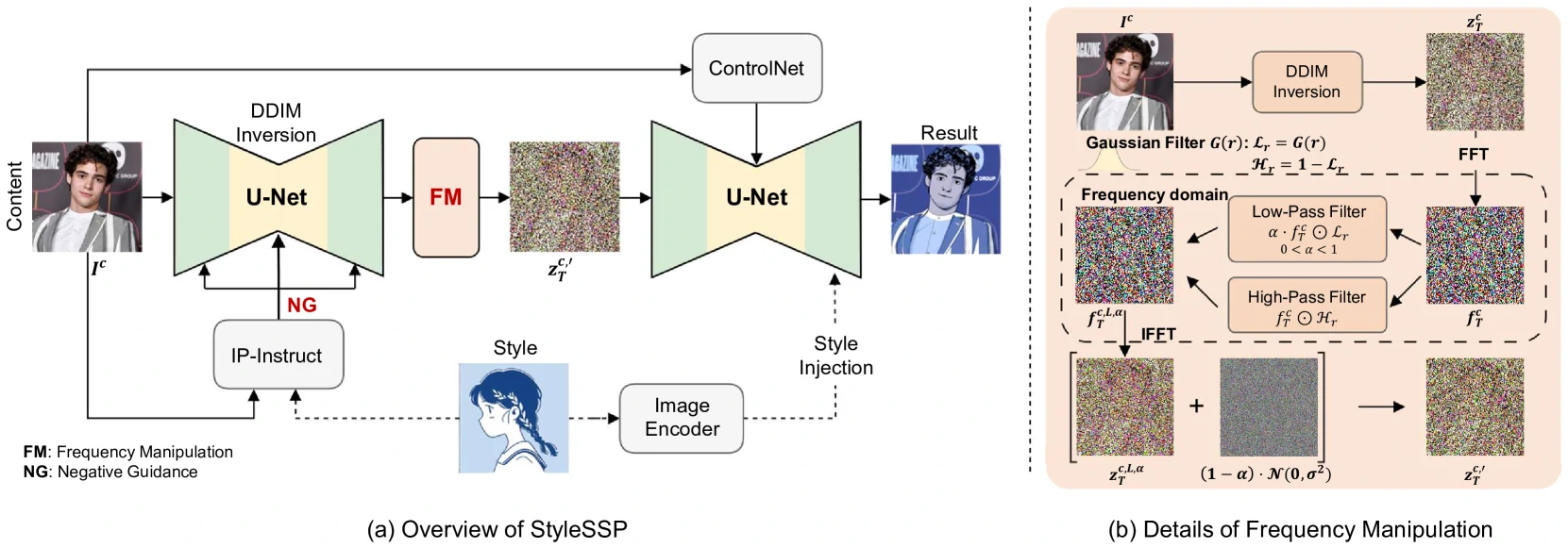
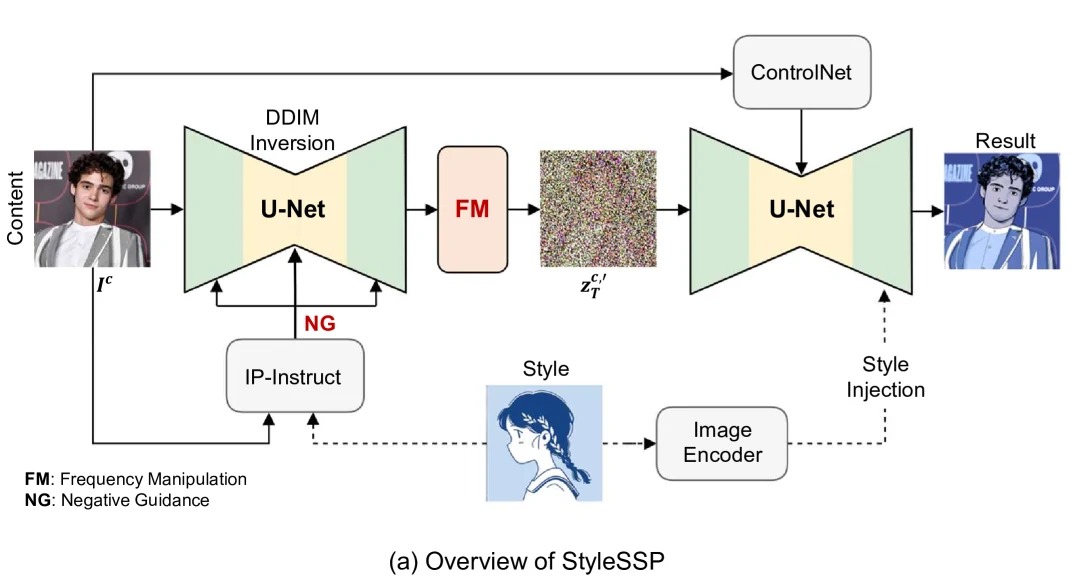
方法步骤
- DDIM 反演得到内容图潜变量
- 在反演阶段加入负引导,让
远离风格图内容,得到期望的内容图潜变量 - 对
做频率操作,削弱低频作为采样起点 - 风格图编码后,采样时仅在对应 U-Net 块注入特征,并使用 ControlNet 保持布局

前置知识
Stable Diffusion
- Stable Diffusion 先将图像编码为潜变量
,在潜空间加噪/去噪,再解码回像素。通过将随机噪声向量 与文本 prompt 映射到输出图像 ,并使用交叉注意力,使输出图像与条件 prompt 语义对齐 - 学习目标是使
最小(去噪回归):
:输入图片; :编码后潜变量; :从 中均匀采样的时间步; :对 使用 text encoder 后生成的文本嵌入; :真实噪声; :U-Net 预测噪声。 - 通过预训练的扩散模型逐步预测并去除噪声来还原图像
Classifier-Free Guidance(CFG)
无分类指引通过引入空文本 embedding
:guidance scale,用于调节条件预测 与无条件预测 的相对权重。
Denoising Diffusion Implicit Model(DDIM) Inversion
去噪扩散隐式模型 通过非马尔可夫扩散过程提升生成效率与质量,减少生成所需步数。在 SD 中,确定性的 DDIM 采样利用 denoiser 网络
- 其中
是定义 个 diffusion 步的噪声强度超参数。本文采用公开的 SD 模型:正向扩散应用在图像编码 上,反向扩散结束后通过解码器获得图像
将 DDIM 采样表示成常微分方程,则 反演过程(正向) 可写为:
其中
表示 DDIM 反演过程中的潜变量特征。由此可以得到 DDIM 反演轨迹 。已有工作表明将 作为采样起点最有利于原始内容保持。 作用:用真实图的噪声轨迹替代纯随机噪声,显著提升内容与布局保持。
具体方法与超参
负引导(Negative Guidance via Inversion)
采用预训练的 IP-Instruct 作为风格与内容的图像特征提取器,提供 embedding 用作负向引导信号,绕开“用文本描述风格 / 内容”的难题。
- 负 prompt 可能与原始 prompt 发生冲突而被模型忽略,需要细致调参
- 自然语言的表达能力有限,任务中很难完全精确地描述一幅图像的内容与风格
- 这些限制削弱了负 prompt 引导的有效性。
在 DDIM 反演前替换噪声预测为带负 prompt 的形式,直接作用于起点:
比采样阶段的负prompt更能避免多条件冲突,减少风格物体泄漏
负引导尺度
:从 1.0 提升到 3.0 可逐步降低风格泄漏,可按偏好调节,默认 1.5
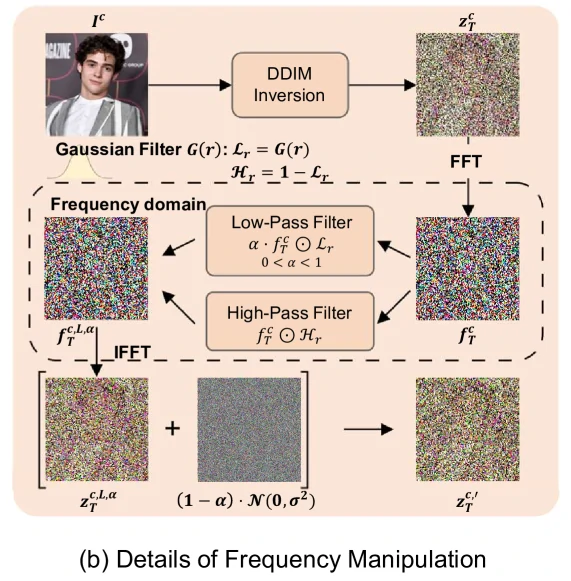
频率操作(Frequency Manipulation)
- 已知:高频成分主导轮廓/布局,低频成分影响较小
- 做法:在频域将低频衰减为
倍,同时按 比例注入高斯噪声,得到强调高频的 - 效果:
增大可锐化轮廓,推荐 0.7
风格注入与内容控制
- 风格注入:只在 U-Net 第一上采样块注入颜色/材质/气氛,避免全层污染内容
- 内容控制:使用 ControlNet-tile 维持原图空间结构
- 组合:反演负引导 + 频率操作 + 轻量风格注入 + ControlNet → 风格、内容兼顾
实验
对比实验
- 预训练的 Stable Diffusion XL + 共 50 个时间步的 DDIM 反演与采样。内容图来自 MS-COCO,风格图来自 WikiArt,随机选取图像对生成 800 张风格化图像
- 评估指标:ArtFID(综合风格/内容,更贴合主观)、FID(风格)、LPIPS(内容)
- 对比 StyleID、InstantStyle plus 到 DiffStyle 等内容保持最佳,风格传输也最优
| Metric | Ours | StyleID | InstantStyle plus | StyleAlign | InstantStyle | DiffuseIT | InST | DiffStyle |
|---|---|---|---|---|---|---|---|---|
| ArtFID (↓) | 21.499 | 28.801 | 25.886 | 36.269 | 37.524 | 40.721 | 40.633 | 41.464 |
| FID (↓) | 13.448 | 18.131 | 16.097 | 20.338 | 21.817 | 23.065 | 21.571 | 20.903 |
| LPIPS (↓) | 0.4881 | 0.5055 | 0.5140 | 0.6997 | 0.6446 | 0.6921 | 0.8002 | 0.8931 |

消融实验
- 组件增量:Baseline → +FM → +NG → StyleSSP
- 频域操作效果较好,但单独用负引导与负prompt区别不大,结合效果却突飞猛进
| Configuration | ArtFID (↓) | FID (↓) | LPIPS (↓) |
|---|---|---|---|
| Baseline | 26.683 | 16.205 | 0.5509 |
| + FM | 24.112 | 15.103 | 0.4973 |
| + NG | 26.542 | 16.128 | 0.5496 |
| StyleSSP | 21.499 | 13.448 | 0.4881 |
结论与思考
- 贡献:系统研究“采样起点”在训练自由风格迁移中的关键性,提出频率操作 + 反演负引导起点组件,增加两个可调参数
与 - 效果:在免训练的前提下同时提升 内容保持与风格匹配,避免风格内容泄漏
- 局限:
- 依赖高质量基础模型(SDXL + IP-Instruct + ControlNet),推理成本较高
- 频率比例
与负引导尺度 仍需经验调参 - 在 艺术性较强的雾化/梦幻风格的网络艺术 或 长曝光/强运动模糊 等场景中,图像本身缺乏清晰边界,高频部分的信噪比降低,此时增强高频不一定更好保结构,反而可能仅带来有限收益甚至放大噪声。同时,这类场景下 ControlNet 等结构控制分支也难以提取可靠边缘,进一步削弱了整体方法的有效性。
- 可能的后续工作:自适应、分块、更细粒度的频域分析与操作方法…
- Title: StyleSSP
- Author: 155TuT
- Created at : 2025-12-04 12:00:00
- Updated at : 2025-12-04 04:46:44
- Link: https://155tut.github.io/2025/12/04/learn-of-stylessp/
- License: This work is licensed under CC BY-NC-SA 4.0.